Computer Vision Training Data
Get high-quality, human-validated computer vision training data – built for image, video, and vision-language models at scale.
LXT delivers domain-specific datasets and evaluation workflows to power your computer vision systems. From object detection and segmentation to video understanding and multimodal visual reasoning, we provide the structured data, secure delivery, and expert QA to support AI vision at enterprise scale.
Our Computer Vision training data by modality
Image
-
Bounding box, polygon, and keypoint annotation
-
Semantic and instance segmentation
-
Attribute and state labeling (e.g., damaged, occluded)
-
Object detection and classification
-
Mask generation and quality filtering
Video
-
Frame-level annotation with object tracking
-
Action and gesture detection
-
Temporal segmentation and scene transitions
-
Multi-object and ID-based tracking
-
Human pose, emotion, and interaction labeling
VLMs
(Vision-Language Models)
-
Image-caption pairs and scene descriptions
-
VQA (Visual Question Answering) data
-
Image-text alignment and correction
-
Text-to-image input/output scoring
-
Multilingual, cross-modal training datasets
Why leading AI teams choose LXT for Computer Vision training data
Why leading AI teams choose LXT for Computer Vision training data

Human-in-the-Loop Workflows
Trained experts annotate and review every image and video.

Multimodal Expertise
Data for standalone CV models and VLMs, globally sourced.

Custom Datasets by Industry
Retail, automotive, healthcare, robotics – your domain, your data.

Evaluation Built-In
Safety, accuracy, and consistency checks at every stage.

Global Workforce at Scale
8M+ contributors and 250K+ experts in 1,000+ locales.

Enterprise-Grade Accuracy
Multi-tier QA, analytics, gold tasks, and full transparency.
Where LXT Fits in Your Computer Vision Stack
Computer vision models vary by application – from static image recognition to dynamic multimodal systems. Each use case requires a tailored mix of computer vision training data, annotation methods, and evaluation processes. Here's how LXT supports your vision AI development:

Object Detection & Classification
Detect and label objects in images with high precision.
What You Need:
Diverse image corpora, accurate bounding boxes, rare class coverage
LXT Delivers:
Segmentation & Pixel‑Level Vision
Understand scenes at the pixel level across object and background boundaries.
What You Need:
Semantic and instance masks, polygon and keypoint detail
LXT Delivers:
Video Tracking & Temporal Analysis
Track objects and activities consistently across video frames.
What You Need:
Frame‑by‑frame tracking, ID consistency, temporal event tags
LXT Delivers:
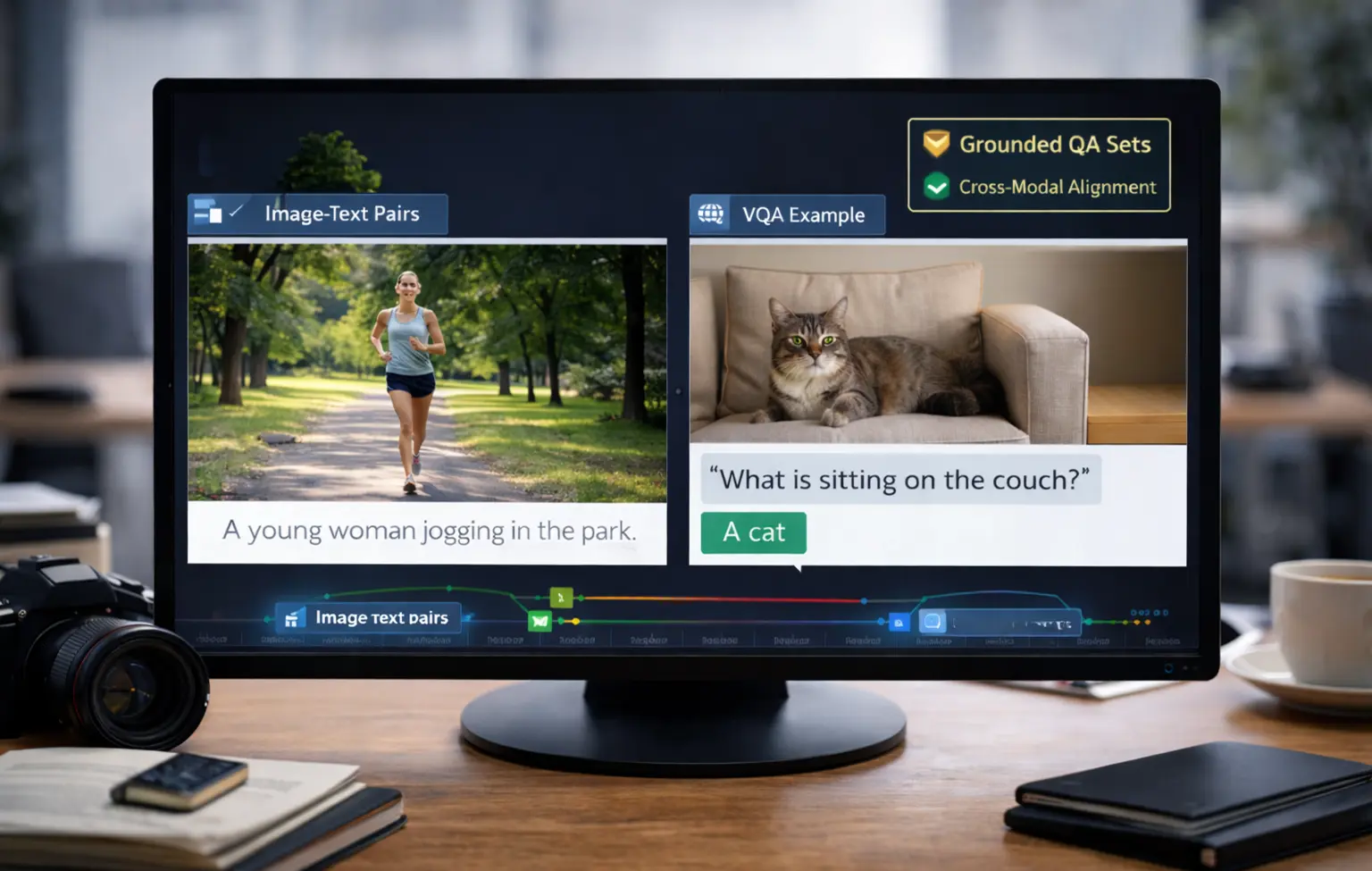
Vision‑Language Models (VLMs)
Connect visual inputs with natural language understanding.
What You Need:
Aligned image‑text pairs, scene descriptions, grounded QA sets
LXT Delivers:

Autonomous & Robotics Vision
Enable machines to navigate and react within physical environments.
What You Need:
Spatial context, multi‑view data, interaction sequences
LXT Delivers:

Bias & Safety Monitoring in Vision Data
Ensure fair, inclusive, and safe visual AI outputs.
What You Need:
Bias benchmarks, edge‑case evaluation, harmful content review
LXT Delivers:
How we deliver Computer Vision training data
From scoped pilot to scalable delivery – designed for enterprise-grade computer vision
Step-by-Step Process

1. Define scope & success metrics
We work with your team to determine the right data types, annotation needs, visual complexity, and quality benchmarks to support your computer vision objectives.

2. Pilot with gold data & workflow validation
A controlled pilot phase tests annotation accuracy, visual edge cases, and workflow setup before full production.

3. Guideline refinement & contributor preparation
We refine task guidelines based on pilot insights, align contributors with your domain and modality requirements (e.g., image, video), and ensure readiness through trial runs.

4. Scaled production with built-in QA
Your computer vision training data is delivered with multi-layered quality checks – including expert review, gold tasks, and performance analytics.

5. Human-in-the-loop evaluation
We support visual model evaluation with structured review tasks – from bounding box accuracy to edge case verification and relevance scoring.

Secure delivery & continuous improvement
Final datasets and evaluation results are transferred securely. Feedback from production is used to enhance future data runs and ensure ongoing alignment with your model needs.
Quality assurance in Computer Vision training data projects
- Layered review pipelines
Each visual dataset is checked through structured workflows involving expert annotators, QA reviewers, and randomized spot checks. - Embedded gold tasks for consistency
Reference images and benchmark labels are embedded in production to validate annotation accuracy and flag potential drift. - Expert-guided instruction calibration
Domain specialists and computer vision experts help refine guidelines and supervise complex annotation tasks like segmentation or keypoint labeling. - Real-time QA visibility
Dashboards provide insights into labeling accuracy, inter-annotator agreement, and project throughput at each stage of delivery.


Enterprise-grade security & compliance for vision data projects
-
Secure infrastructure
LXT operates ISO 27001–certified data delivery centers across Canada, Egypt, India, and Romania – ensuring enterprise-grade protection for visual data. -
Privacy-first data handling
We follow GDPR and HIPAA-aligned practices with secure file exchange, PII redaction, VPN/VPC configurations, and rigorous access controls. -
Flexible legal support
We adhere to your preferred legal framework or provide standard NDAs – covering every stage of the data lifecycle with full confidentiality.
Real-World use cases for Computer Vision training data
Computer vision data powering real-world AI applications – across industries and functions.

Contract Analysis & Document Vision
Enable AI to read, interpret, and extract information from legal or structured documents.
→ Visual document segmentation, table detection, OCR annotation, entity tagging

Healthcare Imaging AI
Train models to detect conditions, segment tissues, or triage clinical visuals.
→ Medical image annotation, diagnostic bounding boxes, anomaly detection, multi-class labeling

Retail & Product Recognition
Boost eCommerce and in-store automation with visual recognition systems.
→ SKU-level product labeling, shelf detection, packaging segmentation, style and brand classification

Autonomous Systems & Robotics
Equip robots and vehicles with the ability to perceive and act within physical environments.
→ LiDAR-camera fusion datasets, spatial labeling, object tracking, trajectory and interaction annotation
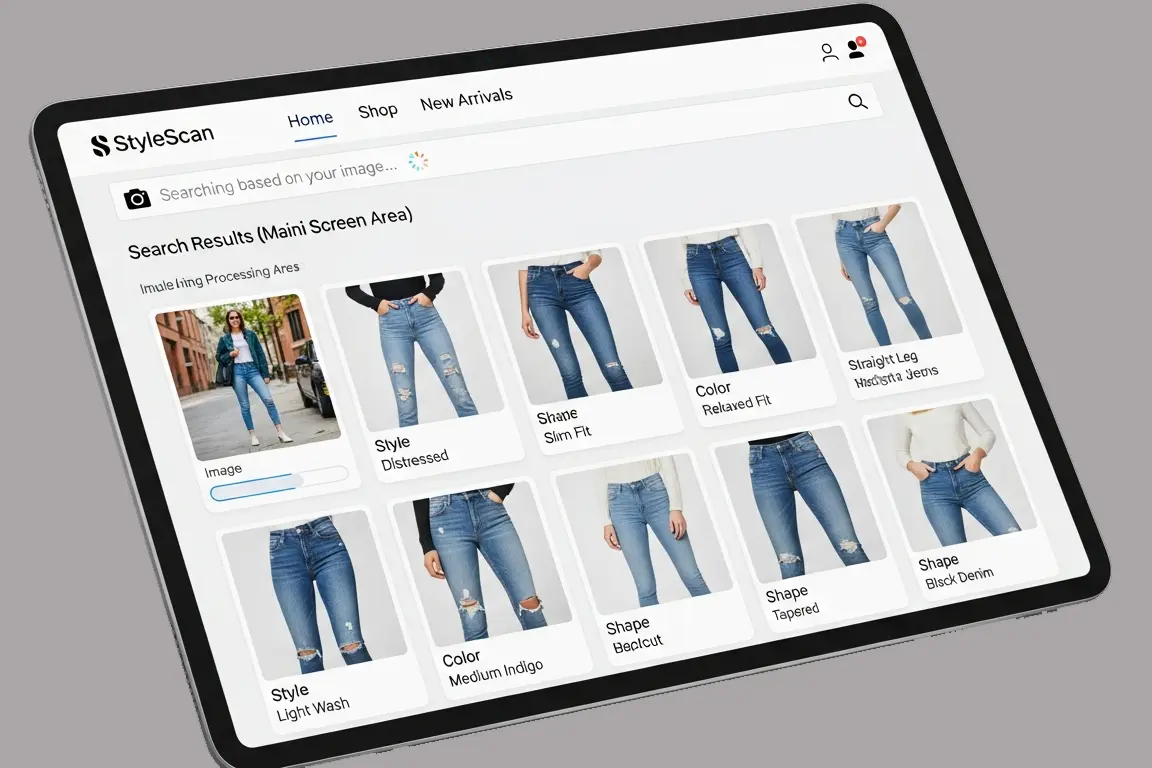
Visual Search & Recommendation
Enable AI to understand visual preferences and enhance product discovery.
→ Style tagging, color/shape metadata, multimodal image-text alignment, user-preference labeling

Safety & Harmful Content Filtering
Detect, classify, and filter sensitive or unsafe visual content.
→ Hateful imagery detection, NSFW classification, visual bias benchmarking, adversarial content curation

Reliable AI data at
scale — guaranteed
FAQs on our Computer Vision training data services
LXT provides computer vision training data for tasks such as image classification, object detection, semantic segmentation, instance segmentation, video tracking, and vision-language alignment for VLMs.
Yes. We deliver domain-specific computer vision training data for healthcare, manufacturing, retail, and other industries—validated by experts to ensure quality and compliance.
Absolutely. We annotate computer vision training data for video tasks, including frame-by-frame labeling, object tracking, motion analysis, and temporal event tagging for real-time applications.
Our computer vision training data workflows include multi-layer quality checks, gold tasks, expert reviews, and continuous benchmarking to maintain precision across large-scale projects.
Yes. In addition to generating computer vision training data, LXT supports output validation, safety checks, and structured evaluation—especially for vision-language and robotics systems.
All computer vision training data projects are managed through ISO 27001-certified centers with GDPR/HIPAA alignment, secure file transfers, and NDA-based data handling protocols.