NLP Training Data
Get the NLP training data you need – high-quality, multilingual, and expert-validated across domains and modalities.
LXT delivers precise training data and human-in-the-loop evaluation for NLP systems of any scale. From intent recognition and NER to search relevance and semantic understanding, we support your models with curated datasets, secure workflows, and global linguistic expertise.
NLP training data by modality
Text
-
Intent classification, slot filling, and semantic parsing
-
Named Entity Recognition (NER) and sentiment annotation
-
Query rewriting and text normalization
-
Document classification and topic modeling
-
Custom dataset creation for domain-specific NLP
Audio-Speech Data
-
Wake word and keyword spotting datasets
-
Emotion and sentiment detection in speech
-
Intent-labeled voice commands
-
Multilingual and accented speech collection
-
Natural conversations for context-aware NLP
Transcription
-
Speech-to-text transcription for conversational and scripted audio
-
Time-coded transcripts for alignment and searchability
-
Domain-specific content (e.g., medical, legal, customer service)
-
Speaker diarization and role labeling
-
Post-editing of ASR outputs
Video
-
Subtitle generation and correction
-
Spoken language transcription and tagging
-
Multimodal sentiment and emotion annotation
-
Audio-visual alignment for instructional or customer support videos
-
Video-based intent detection and task decomposition
Why leading AI teams choose LXT for NLP training data
Why leading AI teams choose LXT for NLP training data

Human Intelligence Built‑In
Expert linguists and human reviewers ensure nuanced, context‑aware data.

Multimodal & Multilingual
Text, audio, transcription, video – across 1,000+ language locales.

Precision Across Domains
From legal to finance to healthcare: NLP training data tailored to your product and industry.

Robust Model Evaluation
Services for evaluation sets, relevance scoring, QA tasks, and error analysis.

Built to Scale
8M+ contributors, 250K+ domain experts, ISO‑certified delivery centers.

Guaranteed Accuracy
Multi‑layer QA, gold tasks, expert review, analytics dashboards.
Where LXT Fits in Your NLP Stack
NLP systems vary widely in architecture and purpose. Whether you’re building chatbots, search assistants, parsing engines or voice interfaces, each use case demands a different mix of curated training data, annotation depth, and human evaluation. Below is a pain‑point overview and how LXT supports them.

Intent & Slot Models
Understand user goals and extract relevant data points from queries.
What You Need:
Intent variation data, domain-specific queries, slot value annotation
LXT Delivers:
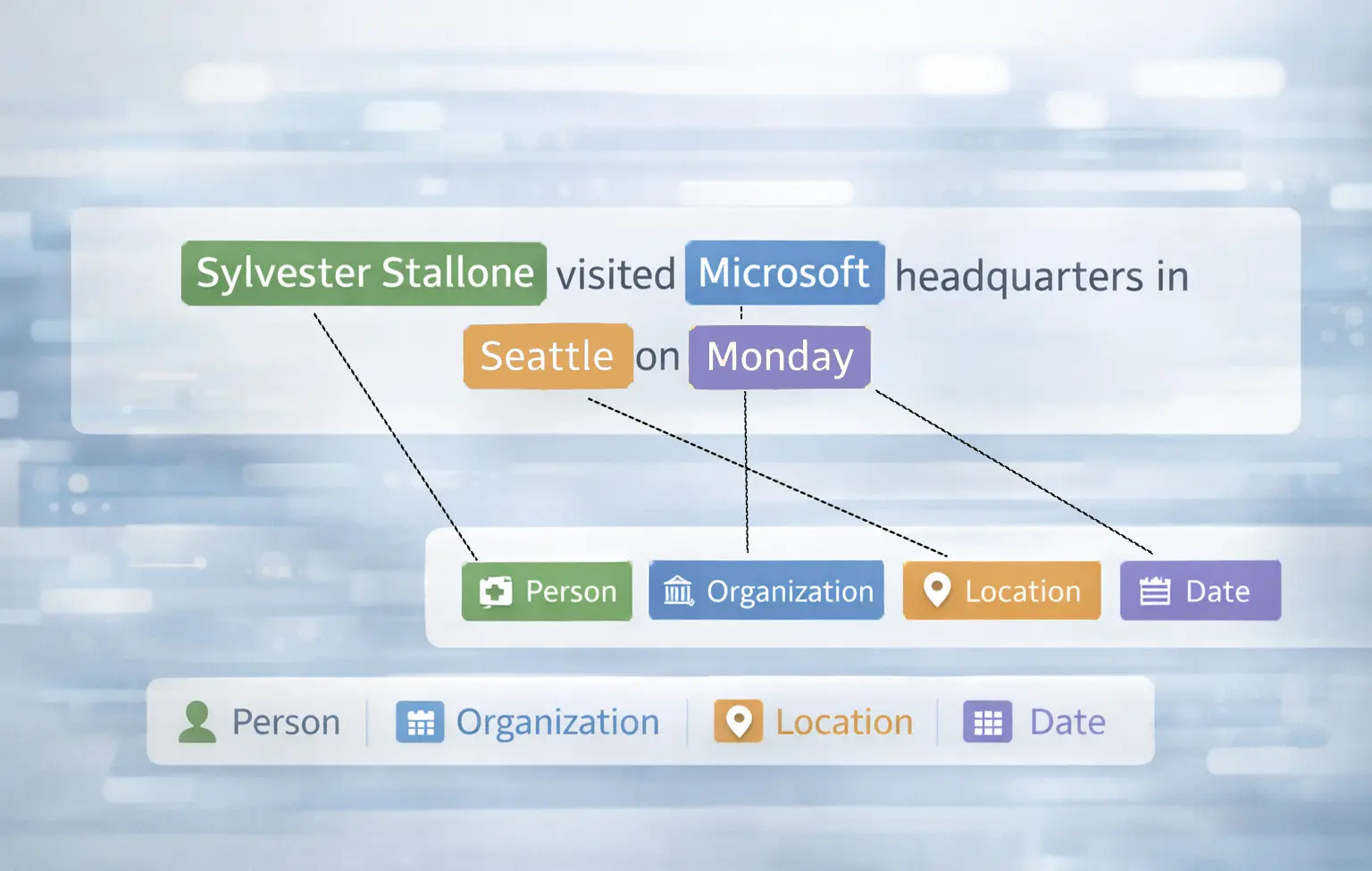
NER Systems
Identify and classify people, organizations, locations, and other entities.
What You Need:
Diverse corpora, entity glossaries, contextual edge cases
LXT Delivers:
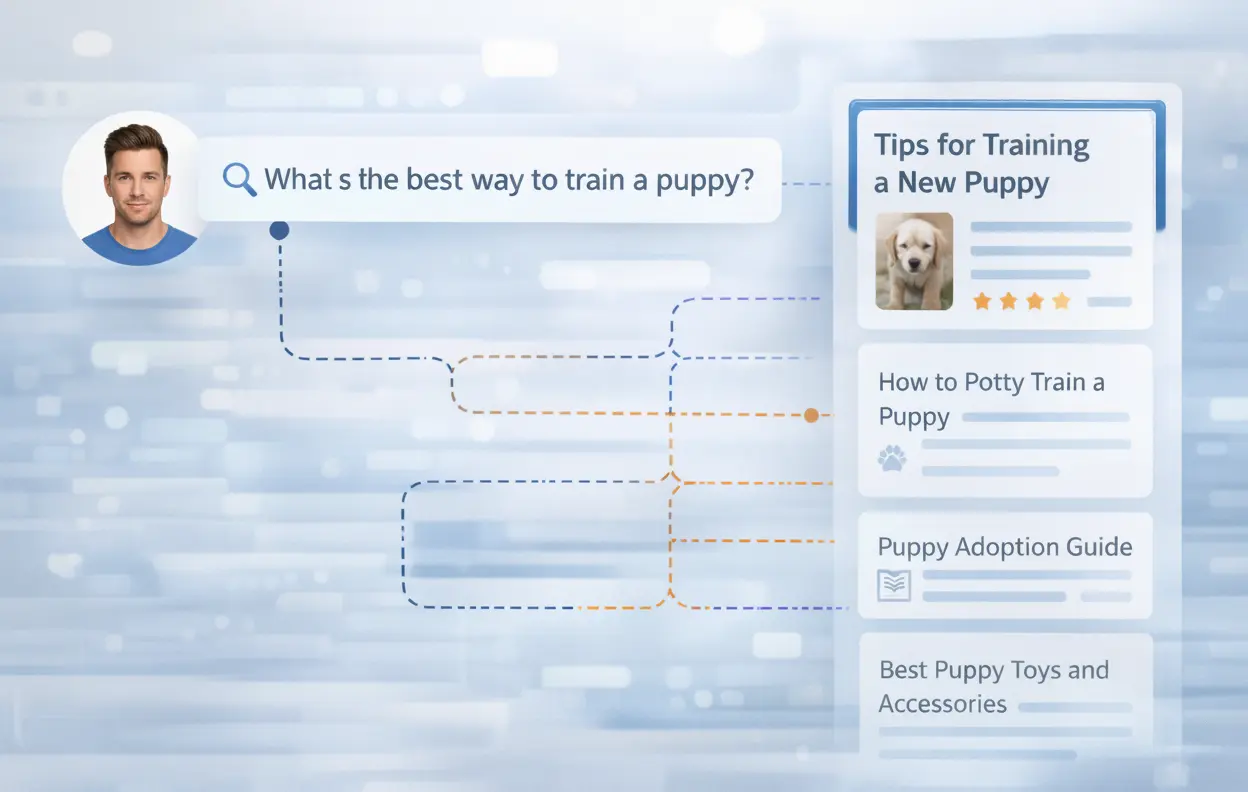
Semantic Search & Retrieval Systems
Match queries with the most relevant documents or content.
What You Need:
Query-doc pairs, relevance judgments, paraphrases
LXT Delivers:
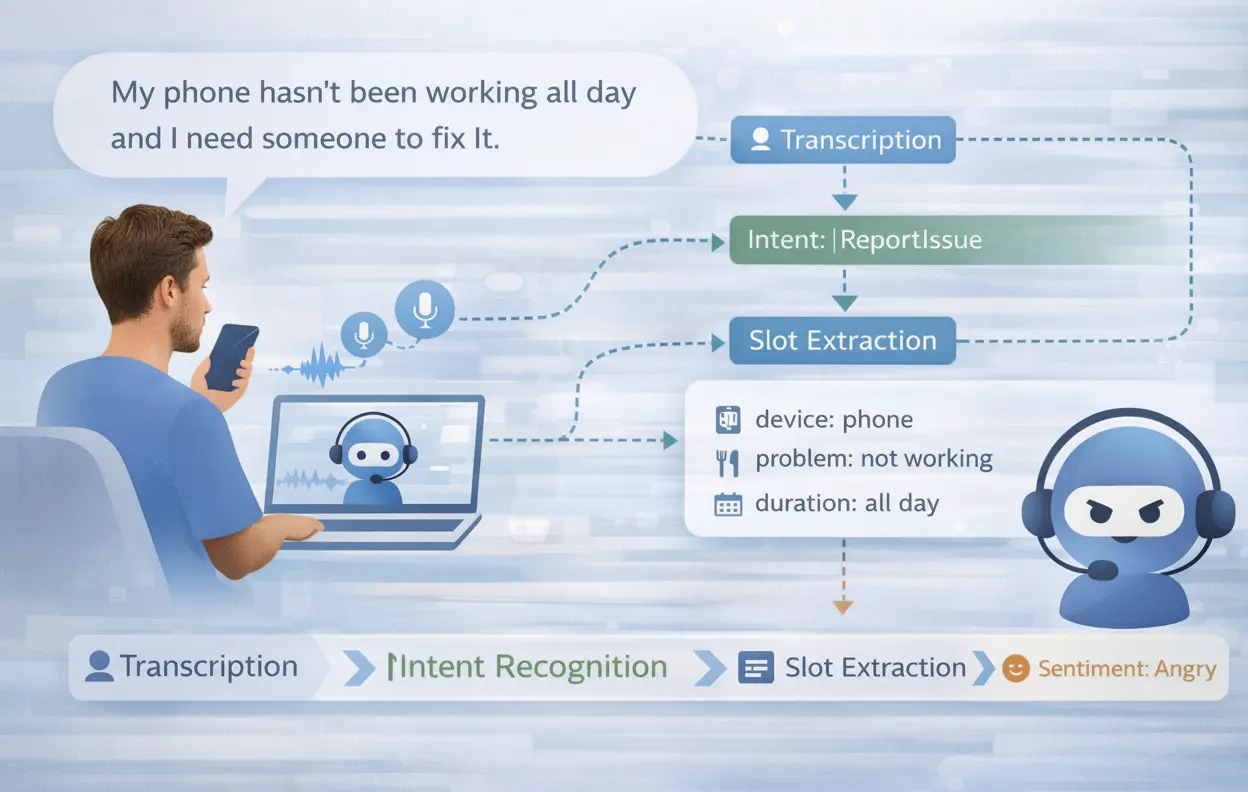
ASR + Spoken Language Understanding
Extract meaning and intent from spoken language.
What You Need:
Transcribed audio, labeled intent/slot, speaker diarization
LXT Delivers:

Multilingual NLP Models
Support accurate NLP across languages, dialects, and cultures.
What You Need:
Parallel corpora, translation QA, cultural nuance handling
LXT Delivers:

Bias, Toxicity & Safety Monitoring
Ensure NLP systems are fair, inclusive, and trustworthy.
What You Need:
Bias benchmarks, adversarial content, toxicity tagging
LXT Delivers:
How we deliver training data for NLP
From scoped pilot to scalable delivery – designed for enterprise NLP
Step-by-Step Process

1. Define scope & success metrics
We collaborate with your team to define data types, language coverage, domain specificity, quality targets, and intended NLP use cases – ensuring the dataset fits your model goals.

2. Pilot with gold data & workflow validation
A small-scale pilot helps calibrate instructions, validate annotation quality, and fine-tune delivery workflows before scaling.

3. Guideline refinement & contributor preparation
We update task guidelines based on pilot results, align contributors with domain needs, and run test tasks to ensure readiness.

4. Scaled production with built-in QA
Your NLP training data is delivered at scale with multi-pass quality control, including expert review, spot checks, and analytics.

5. Human-in-the-loop evaluation
We support human review of model outputs, ambiguity resolution, and scoring for relevance, intent, or correctness.

6. Secure delivery & feedback loop
Final data sets are transferred via secure channels. Project insights inform ongoing quality improvement or future data runs.
Quality assurance in NLP training data projects
- Structured multi-layer reviews
Each dataset is reviewed through layered workflows involving trained annotators, reviewers, and targeted spot checks. - Reference tasks for quality control
Embedded benchmark items are used during pilots and production to maintain annotation consistency and detect drift. - Expert-led guideline validation
Linguists and domain specialists refine instructions and oversee complex language-specific annotation tasks. - Live performance tracking
Dashboards offer visibility into annotation accuracy, reviewer agreement, and throughput metrics across the project lifecycle.


Enterprise-grade security
& compliance
-
Secure infrastructure
ISO 27001 certified delivery centers in Canada, Egypt, India, Romania
(five total certified sites) -
Data privacy by design
GDPR, HIPAA compliance.
PII redaction, secure file handling, VPN/VPC options. -
NDAs and legal coverage
We support your preferred legal framework or provide standard NDAs.
Discover AI data collection and annotation best practices for speech and NLP
Real-World use cases for training data for NLP
NLP training data powering enterprise AI applications – across industries and functions.

Contract Intelligence
Train NLP systems to extract, classify, and summarize legal clauses or compliance risks.
→ Clause annotation, entity recognition, document classification, multilingual contract parsing

Healthcare NLP Solutions
Enable systems to understand clinical text and support diagnosis, triage, or research.
→ Medical transcription, terminology normalization, entity linking, bias detection in sensitive language.
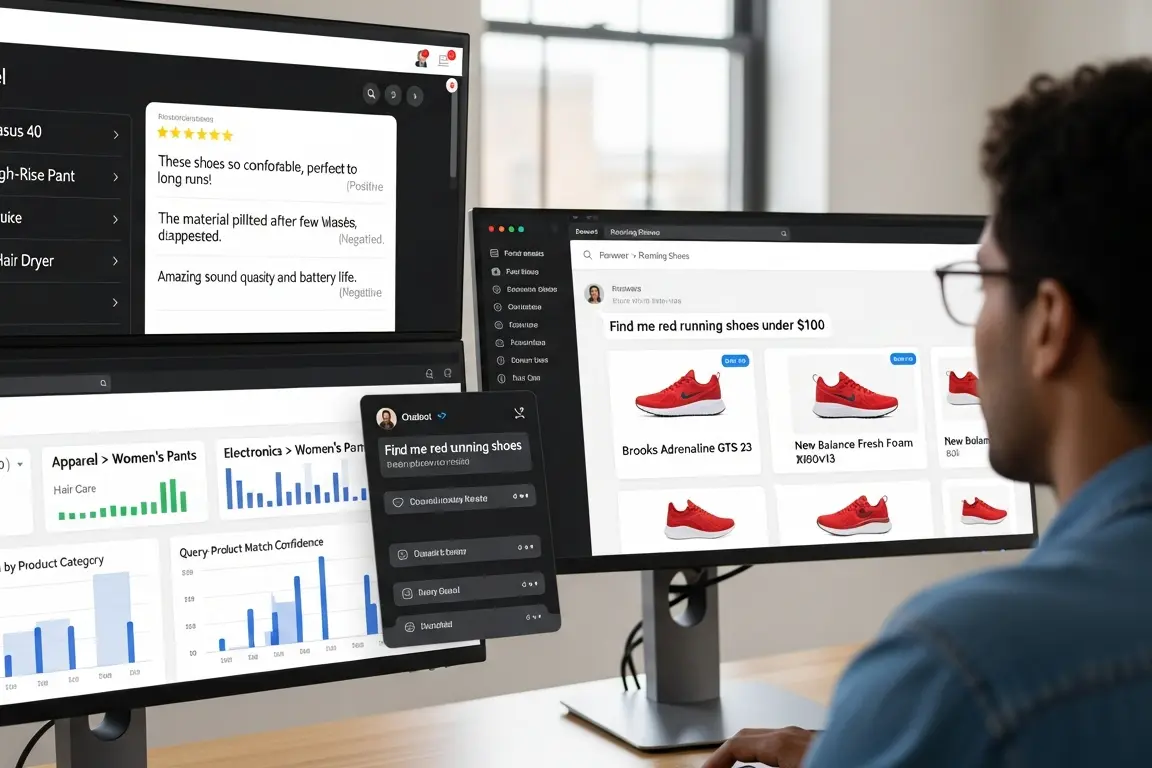
Retail & eCommerce NLP
Power personalized shopping experiences and product discovery with NLP-driven systems.
→ Search relevance training, product categorization, sentiment-tagged reviews, chatbot dialogues

Enterprise Knowledge Search
Build AI assistants that navigate and retrieve content from internal documentation.
→ Semantic chunking, FAQ mining, instruction-following datasets, retrieval optimization
Conversational Interfaces
Develop NLP models for voice assistants, IVR systems, and customer support bots.
→ Dialogue data, intent classification, entity annotation, escalation labeling

Multilingual Content Understanding
Extend NLP performance across regions and languages with culturally aware data.
→ Parallel corpora, machine translation post-editing, language-specific tokenization and labeling

Reliable AI data at
scale — guaranteed
FAQs on our NLP training data services
Pricing depends on task complexity (e.g., NER vs. semantic search), volume, language coverage, and turnaround time. We provide a tailored quote after a short scoping call.
Yes. We support mutual NDAs and enterprise data‑handling requirements, including secure delivery and legal alignment.
Through gold tasks, multi‑layer QA, expert calibration, benchmarking, and analytics to ensure consistent accuracy and label integrity.
We support intent/slot systems, NER, semantic search, parsing, ASR/SLU, multilingual NLP, and bias/safety evaluation tasks.
Pilots typically begin within 1–2 weeks of scope confirmation. Full production follows after guideline refinement and QA alignment.
Yes. We provide human judgments, relevance scoring, bias tagging, and comprehensive evaluation workflows.